Malzoo Serverless: The what, why and how
What is Malzoo Serverless
Malzoo is one of my first projects and since it’s release in 2016 has made significant steps forward in it’s purpose to perform mass static file analysis for researching clusters based on static file properties. Now at 4 years of age, it is time to look how the idea of mass static file analysis can be deployed with new technologies like Docker and the Cloud.
Malzoo Serverless is the translation of the malzoo project to the Serverless concept. This means no virtual machines are required and need to be maintained (patched, run 24/7 etc) and code is executed on an event basis (event-driven).
Why Serverless?
The Serverless concept allows us quicker deployment of new features and offers pay-for-use instead of having a virtual machine running 24/7. The advantage of the Cloud is also in scalability. It does not mather much if you submit 10 or 1000 samples. And deployment is also easy. All you have to do is clone the git repository, run the deploy commands (check the “How to deploy and submit samples” section for details) and you are ready to go.
Serverless has some gotchas that can cost you some bucks if not careful. You can read those in my blog post here
Architecture
The architecture for Malzoo Serverless consists of:
- One S3 bucket, for storage of the samples and triggering the distributor Lambda
- Three Lambda with Python runtimes
- The distributor, determines to which queue the sample needs to go based on filetype
- The Exeworker, analyses executable samples
- The Docworker, analyses Microsoft Office documents
- The Otherworker, analyzes all other files, calculating the hash and filesizes
- Three SQS queues, one for each filetype currently supported and one for unclassified files
- One DynamoDB database, where the results are stored by the worker Lambda

The Lambda workers have two layers (simply put: self-created libraries for Python to import) that are used to hash files and to submit the sample data to the DynamoDB database. This approach makes sure files and results are handled the same across workers and reduces code duplication across functions.
How to deploy and submit samples
Deploying the application is easy with AWS Serverless Application Model (SAM). With this tool you can locally build, invoke and deploy the Lambda functions and keep everything in one CloudFormation stack.
Prerequisites
- Active AWS subscription
- AWS CLI installed and configured
- AWS SAM installed and configured
- Docker installed
- Some malware samples to submit (checkout TheZoo for a bunch)
Deploying
-
To deploy the application, you first need the code, so go ahead and clone it to your local system:
git clone https://github.com/nheijmans/malzoo_serverless malzoo_serverless -
Now you have the code, the easiest way to deploy Malzoo serverless is by using the automate.sh script in the repository.
cd malzoo_serverless/
sh automate.sh
Then follow the guided deployment.
- That should be it! In the output, you should see the name of the S3 bucket that was created in the process. The deployment created a link between the S3 bucket and the analysis Lambda. By copying files for analysis to the S3 bucket, the Lambda distributor will be triggered to send the file to the right worker. Copying a sample to the S3 bucket from the CLI is simple:
aws s3 cp sample.exe s3://<yourbucketname>/sample.exe
Performance & Clustering
Processing time
Sample set used: VirusShare #360
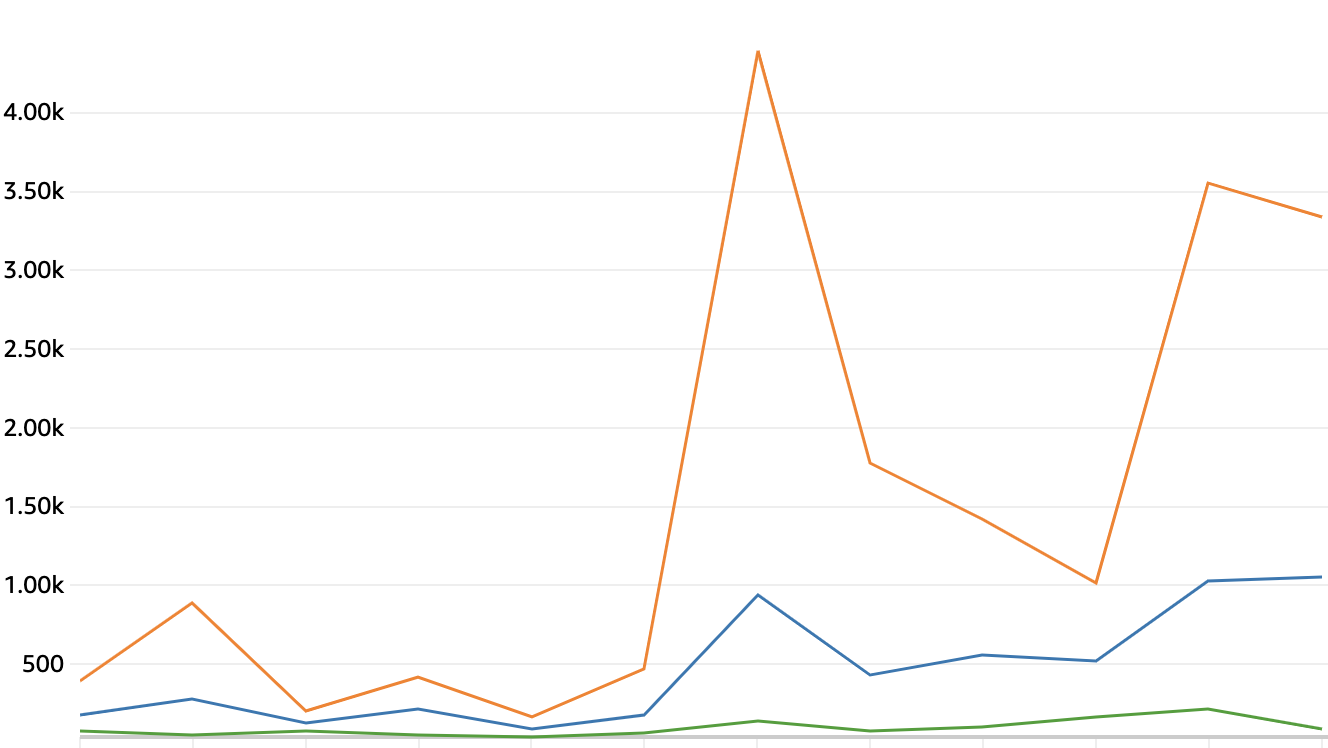
The performance of the Serverless deployment with three concurrent workers, is shown in the graph below. The first 100 executables from the VirusShare sample set are used as source. The average analysis time of samples is between 0.5 and 1 second, as seen in the graph below. The average filesize is 1502 Kb, the smallest 2,5 Kb and the largest 19929 Kb. The Lambda are configured with 128MB memory and 0.25 vCPU.
X-axis: Time of execution (10 minute range)
Y-axis: Time of sample analysis, in milliseconds
Clustering
From the 100 analysed samples, a cluster with similarties based on filesize and compilation time, can be identified. The samples compiled between 2016 and 2018 are selected with epoch (UTC) 1451606400 and 1546300799 and with a filesize between 585 Kb and 634 Kb. Below a screenshot of the query in DynamoDB

From the 100 samples, 10 samples correspond to each other on, for example:
- Anti-Virus signature: GrayWare/Win32.Wacapew
- Compile language: Russian
- Filename: “PlayBlackDesert.exe”
This kind of clustering research can help your cause not only with malware clustering as in the example, but also in Microsoft Office documents with author names, character counts or Macro details when cleaning up old shares.
Next up…
Time for deploying and analyzing files of interest! Have fun :)